bytearray
目录
相关位置文件
- cpython/Objects/bytearrayobject.c
- cpython/Include/bytearrayobject.h
- cpython/Objects/clinic/bytearrayobject.c.h
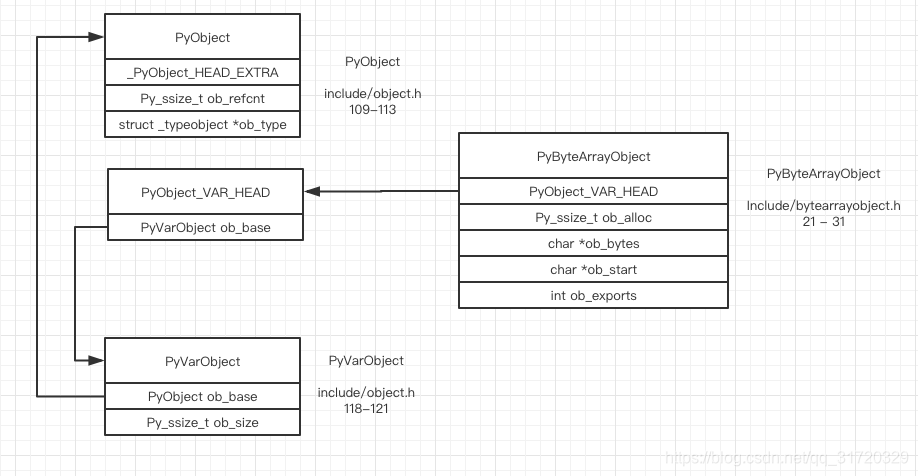
内存构造
ob_alloc 表示了实际分配的字节大小
ob_bytes 表示物理启始位置的地址, ob_start 表示逻辑启始位置的地址(请往下看)
ob_exports 表示有多少个对象正在共享这里面的字节空间, 某种程度上可以当成引用计数器
示例
empty bytearray
>>> a = bytearray(b"")
>>> id(a)
4353755656
>>> b = bytearray(b"")
>>> id(b) # 他们id不同, 不是同一个对象
4353755712

append
增加了一个字符 ‘a’ 之后, ob_alloc 变成了 2, ob_bytes 和 ob_start 都指向同一个地址
a.append(ord('a'))

resize
控制内部实际占用的字节空间的增长速率如代码所示
/*根据策略来控制增长幅度 */
if (size <= alloc * 1.125) {
/* 适度的调大alloc大小, 有点像list的内存分配 */
alloc = size + (size >> 3) + (size < 9 ? 3 : 6);
}
else {
/* 直接设置成需要的大小 */
alloc = size + 1;
}
在这次append操作中, ob_alloc 值为 2, 并且要求的大小也为 2, 2 <= 2 * 1.125, 进入适度调整大小的策略分支, 新的大小变为 2 + (2 » 3) + 3 ==> 5
a.append(ord('b'))

slice
b = bytearray(b"abcdefghijk")

slice 操作之后, ob_start 指向真正的数组内容开始的位置, ob_bytes 仍然指向内存分配的开始位置
b[0:5] = [1,2]

只要 slice 操作是缩减 bytearray 大小的, 并且如下判断 new_size < alloc / 2 不成立, bytearray 就不会在对应的操作下对内存占用重新分配
b[2:6] = [3, 4]

现在, 在缩小的操作中, new_size < alloc / 2 成立, 重新分配被触发
b[0:3] = [7,8]

在 slice 操作中的增长策略和 append 是相同的, 他们都是共用一个函数来调整空间
申请的大小是 6, 6 < 6 * 1.125, 所以新分配的大小为 6 + (6 » 3) + 3 ==> 9
b[0:3] = [1,2,3,4]

ob_exports
ob_exports 这里表示的值是什么意思呢? 你需要先理解 buffer protocol 的概念和设计初衷, 请参考 less-copies-in-python-with-the-buffer-protocol-and-memoryviews 和 PEP 3118
buf = bytearray(b"abcdefg")

bytearray 对象实现了 buffer protocol 的标准, memoryview 可以通过 buffer protocol 去获取对象中的实际的字节块, 而不是拷贝一份, mybuf 和 buf 就是共享同一个内存块
ob_exports 的值变成了 1, 表示有多少个外部对象正在通过 buffer protocol 共享着内部的内存块
mybuf = memoryview(buf)
mybuf[1] = 3

mybuf2 也进行了同样的操作(ob_exports并未增加, 是因为 mybuf2 调用的是 mybuf 的 slice 操作, 增加 ob_exports 是通过调用 buf 的 buffer protocol 定义的c函数完成的)
mybuf2 = mybuf[:4]
mybuf2[0] = 1

ob_exports 现在变成了 2
mybuf3 = memoryview(buf)

ob_exports 现在变成了 0
del mybuf
del mybuf2
del mybuf3
